
A car you can talk to has been a longstanding dream, whether as the basis for television shows or more recent smartphone integrations.
One way of achieving better, more natural voice commands is by incorporating AI foundation models into vehicle systems, which offer more intelligence than traditional voice commands. AI foundation models can connect everyday questions with vehicle functions in a seamless dialogue. These models allow drivers to focus on the road ahead and enjoy every aspect of the journey while making interactions more intuitive.
While large language models (LLMs) offer powerful capabilities, they present one considerable drawback, at least in automotive settings: their reliance on consistent network access makes LLMs impractical for in-vehicle use due to potential lag and interruption.
To deliver reliable, next-level intelligence, BMW Group and Google Cloud successfully completed a proof of concept to build an efficient, reproducible solution to automate the workflows for fine-tuning, optimizing, evaluating, and deploying language models for specific domains, with special focus on small-language models, or SLMs. In this blog, we want to show results, findings and provide source code to encourage wider adoption.
“Finding the optimal trade-off for small-language models is a challenging, iterative process,” Dr. Celine Laurent-Winter, vice-president for Connected Vehicle Platforms at BMW Group, said. “Automating the workflow for training, testing, and deploying domain-specific SLM allows a big push for our development efficiency. With automated pipelines, we can rapidly adapt models to our domain and rigorously test and evaluate them against domain-specific benchmarks. This allows us to iterate and optimize models in hours rather than days, in an automated, reproducible workflow.”
Small language models: small concept, big potential
Generative AI offers automakers powerful new capabilities, enabling complex voice commands. Before, it would have been almost impossible for a voice command system to understand a request like: “Find me a restaurant with vegetarian offerings along my route that is open now and has a customer rating higher than four stars.” With its language understanding and reasoning capabilities, gen AI can puzzle out such a request.
Integrating this intelligence, however, presents a challenge: Cloud-based LLMs are powerful but rely on a stable network to avoid frustrating lag. Conversely, onboard LLM are constrained by a vehicle’s limited computing hardware.
Small language models may offer an ideal balance — but finding the right trade-off between size and capability requires careful optimization.
These purpose-built, right-sized generative AI models can be run directly on edge devices, including vehicles. A common approach is having the SLMs handle the most frequently used features locally and only routing more complex requests to a cloud-based LLM. An SLM must be small enough to run on the target device, yet capable enough to be useful — especially when tailored to the specific automotive context via fine-tuning
Challenges of integrating foundation models into vehicles
Compared to the cloud, vehicle infotainment systems have limited storage and computing power. A 5 Series sedan or X3 SUV might look big, but there’s still limited space given all the performance, technology, and luxury that must fit between their four wheels.
Therefore, integrating a large language model, such as Gemma 3 27B which can consume over 40 GB of memory at 16-bit precision, is difficult. While smaller versions exist (e.g., Gemma 3 270M), they still tend to have a broad, generalized focus albeit with potential reduced accuracy compared to bigger models.
Hence, model compression (to reduce size) and tuning (to ensure high accuracy) become necessary for specialized use cases like ours. The goal then is finding the best tradeoffs between model size, inference time, and accuracy for the most frequent tasks.
Converting LLMs to SLMs
Turning large, resource-intensive LLMs into efficient SLMs requires well-known compression and quality enhancement techniques. Here’s a (reduced) overview of common techniques we’ve explored:
Compression techniques:
The primary goal is to reduce the model’s compute and memory complexity. This can be done via:
-
Quantization: Reducing the model’s memory footprint by converting high-precision parameters (e.g., 32-bit floats) to lower-precision formats (e.g., 8-bit integers or 4-bit floats). This leads, however, to a potential, but often minor, reduction in accuracy.
-
Pruning: Systematically identifying and removing the least important parameters or connections within the neural network, streamlining the SLM while retaining core capabilities.
-
Knowledge distillation: A compact “student” model is trained to replicate the performance of a larger “teacher” LLM, transferring complex knowledge into a much smaller, more efficient architecture.
Post-compression quality enhancement
We further engaged methods that can help recover or improve performance lost during compression.
-
Fine-tuning (and LoRA): Adapts the compressed model to a specific domain using targeted datasets. Standard approaches are Parameter-efficient fine-tuning (PEFT), such as Low-Rank Adaptation (LoRA). LoRA freezes the original weights and injects smaller, trainable matrices, dramatically reducing computational and storage costs while matching the performance of full fine-tuning.
-
Reinforcement Learning (RL): Methods like Proximal Policy Optimization (PPO), Direct Policy Optimization (DPO), and Group relative policy optimization (GRPO) are used for alignment with human preferences. RL iteratively improves model outputs by rewarding desired behaviors, guiding the model to generate more useful and accurate responses.
Evaluating performance for automotive tasks
Once a model has been compressed and enhanced, a crucial final step is to rigorously evaluate its performance. This covers system performance (e.g., latency, resource utilization on target hardware) and the qualitative assessment of the model’s generated responses. For assessing quality, established methods are:
-
Point-wise evaluation: These methods assess the quality of a single generated response by comparing it against a pre-defined “ground truth” or reference answer. Examples include ROUGE and BLEU metrics.
-
Pair-wise evaluation: This approach determines which of two different model outputs is better, often aligning more closely with subjective human preferences for conversational quality. This can be executed with an Auto-rater (or LLM-as-a-judge) or direct Human Feedback.
Developing a robust testing strategy combining these evaluation methods is essential for validating the success of the compression and fine-tuning efforts.
The challenge of finding the optimal configuration
The path from a general-purpose LLM to a specialized SLM is not straightforward. Every choice — from type of quantization to characteristics and contents of the fine-tuning domain-specific dataset — directly affects the quality and efficiency of the final model. This creates an exponential range of possible configurations each with its own trade-offs.
This intricate landscape is further complicated by practical constraints: Not every compression or enhancement technique is applicable to every language model, and some methods are incompatible. For example, API-only models like Google Gemini permit fine-tuning only through a fixed set of methods.
The sheer volume of viable combinations renders a manual search for the optimal configuration an incredibly tedious, if not impossible, undertaking. To overcome this challenge, we built automated, reproducible workflows through executable pipelines.
Solution: An automated workflow for SLM optimization
Our solution is an automated workflow that orchestrates compression, adaptation, and evaluation steps needed to produce optimized SLMs. This is achieved by designing a flexible pipeline where each step is a modular, parameterized component. This workflow-based approach allows us to systematically explore the vast configuration space and pinpoint the best-performing models for in-vehicle deployment.
The process is structured as a workflow that can be executed automatically on a powerful workflow engine, such as Vertex AI Pipelines. In this workflow, we can define the sequence of operations (e.g., quantization, followed by LoRA fine-tuning and DPO) as a chain of interconnected components. Through pipeline parameters, we can search the entire configuration space, test different base models, compression techniques, tuning methods, and evaluation datasets.
This automated search allows for the comprehensive exploration of possibilities that would be unfeasible to test manually. The final artifacts from each pipeline execution are fully traceable and ready for deployment. This includes the versioned SLM itself, exact configuration parameters that produced the model, datasets used for evaluation, and a detailed report of its performance metrics, ensuring complete reproducibility.
Implementation: An automated workflow with Vertex AI Pipelines
Our solution is built on Google Cloud’s Vertex AI platform, using configurable, executable pipeline templates. This offers a structured and automated way to find optimal SLMs in the vast possible search space. Figure 1 illustrates this workflow, its steps and their interactions with various data and model stores.
Figure 1: High-level overview of the automated pipeline’s steps and its interaction with data and model stores.
Step 1: Versioning and configuration
Every Vertex AI workflow begins in Vertex AI Experiments. This initial step ensures the entire process is version controlled. The chosen LLM and datasets as well as the pipeline’s configuration parameters are all logged as a single, versioned entity, ensuring complete traceability and reproducibility for every experiment.
Step 2: Optimization and compression
This stage puts the compression and enhancement techniques we discussed earlier into practice. Crucially, the pipeline is designed to manage the complex compatibility matrix between models, methods, and parameters. A pipeline template can, for example, enforce that only certain fine-tuning methods are applied to specific model architectures they are known to support, thereby automating the management of these constraints.
Our implementation provides reusable and standardized components for various fine-tuning (e.g., LoRA) and reinforcement learning methods (e.g., DPO, GRPO, and PPO). For compression, we adopt post-training quantization methods mapping models to lower-bit data types (e.g., bfloat16, 4-bit floats, or 8-bit integers) tailored to the target hardware’s specifications.
Step 3: Conversion and deployment testing
Once an SLM is optimized, the pipeline deploys it to an environment. This allows testing if the model deployment succeeds on hardware representative of the target environment. This step provides a crucial, early validation point for the model’s technical viability under realistic conditions.
An example would be running SLM on Android devices directly and natively (i.e. without emulation layers) on compute instances in the cloud. This allows testing how the model works on the target environment.
Step 4: Evaluation
A comprehensive evaluation is conducted to measure the SLM’s true performance. This goes beyond simple accuracy, encompassing hardware-specific metrics like memory usage and inference latency as measured on the cloud-based device emulators. We also assess response quality using a combination of evaluation methods.
This can include point-wise metrics like ROUGE and BLEU, as well as more advanced pair-wise methods like auto-raters. The pipeline is designed to use custom test datasets reflecting a wide range of in-car tasks, such as multi-turn response generation or query rewriting with conversational context. This robust evaluation framework is also forward-looking, with the capability to assess multimodal SLMs such as Google Gemini and Gemma.
Step 5: Visualization and analysis
The Vertex AI Experiments allows storing generated metrics, comparing different experiment runs side-by-side, and creating visualizations using integrated tools like TensorBoard and Looker, making it easy to identify the most promising SLM candidates.
Figure 2: The automated pipeline as viewed in the Vertex AI Pipeline interface.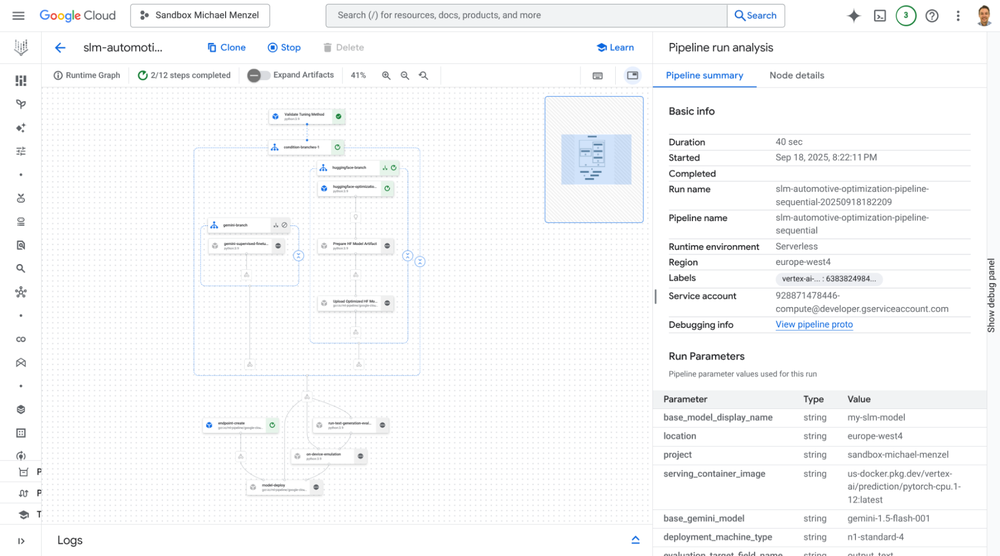
This entire automated workflow, from versioning to evaluation, creates a powerful feedback loop. It enables continuous integration and refinement, allowing teams to rapidly iterate and adapt their SLMs to evolving requirements and discover optimal configurations that would be almost impossible to find via manual efforts.
Conclusion and looking ahead
In this blog, we detailed how the automated workflow built on Google Cloud’s Vertex AI successfully streamlines SLM development. This enables rigorous evaluation which model architectures or types (like Gemini, Gemma, and Llama) offer the best trade-off for our domain regarding performance, accuracy and size.
Crucially, we are linking our approach with the BMW Group’s “Head unit in the cloud”, running the Android Open Source Project (AOSP) based infotainment system natively on cloud compute instances. This allows to test SLMs, including multimodal functions, in a virtual, scalable environment without the need for limited embedded devices.
The BMW Group’s commitment to delivering cutting-edge in-vehicle experiences via artificial intelligence aligns seamlessly with Google Cloud’s expertise in AI and machine learning. As we look ahead, we anticipate a continued partnership that will push the boundaries of what’s possible in automotive AI.
We are publishing the solution of our PoC in the form of a SLM pipeline on GitHub. Feel free to adapt it to your needs and build your own optimized SLM!
This blog was written by Dr. Michael Menzel, Google Inc., and Dr. Jens Kohl, BMW Group, and is based on work done in a PoC which involved Dr. Arian Bär, David Katz, Dr. Felix Willnecker, Dr. Jens Kohl, Karsten Knebel, Dr. Manuel Luitz, Paul Weber, Raphael Perri, Thomas Riedl (all BMW Group) as well as Florian Haubner, Marcel Gotza, Dr. Michael Menzel, Raul Escalante (all Google Inc.).