
This post was originally published on this site
As generative AI moves from experimentation to production, platform engineers face a universal challenge for inference serving: you need low latency, high throughput, and manageable costs.
It is a difficult balance. Traffic patterns vary wildly, from complex coding tasks that require processing huge amounts of data, to quick, chatty conversations that demand instant replies. Standard infrastructure often struggles to handle both efficiently.
Our solution: To solve this, the Vertex AI engineering team adopted the GKE Inference Gateway. Built on the standard Kubernetes Gateway API, Inference Gateway solves the scale problem by adding two critical layers of intelligence:
-
Load-aware routing: It scrapes real-time metrics (like KV Cache utilization) directly from the model server’s Prometheus endpoints to route requests to the pod that can serve them fastest.
-
Content-aware routing: It inspects request prefixes and routes to the pod that already has that context in its KV cache, avoiding expensive re-computation.
By migrating production workloads to this architecture, Vertex AI proves that this dual-layer intelligence is the key to unlocking performance at scale.
Here’s how Vertex AI optimized its serving stack and how you can apply these same patterns to your own platform to unlock strict tail-latency guarantees, maximize cache efficiency to lower cost-per-token, and eliminate the engineering overhead of building custom schedulers.
The results: Validated at production scale
By placing GKE Inference Gateway in front of the Vertex AI model servers, we achieved significant gains in both speed and efficiency compared to standard load balancing approaches.
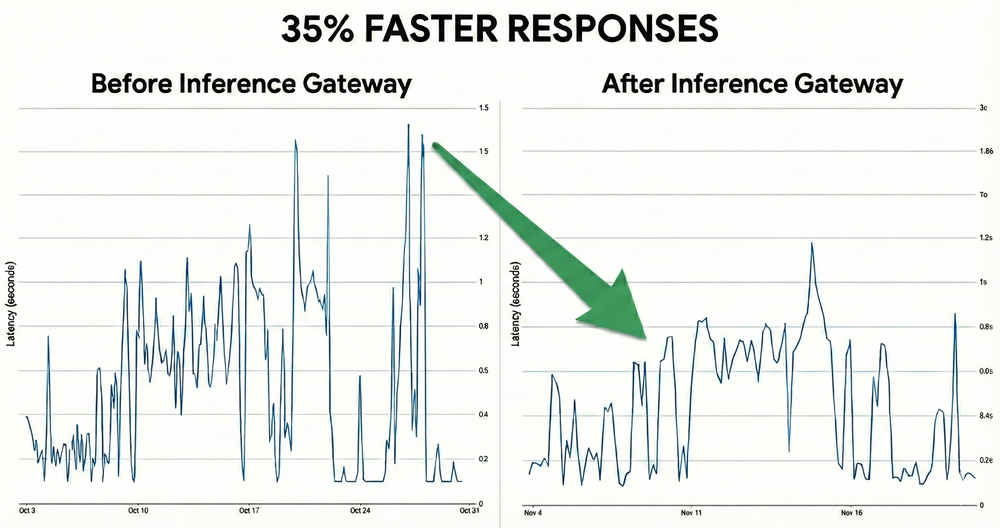
These results were validated on production traffic across diverse AI workloads, ranging from context-heavy coding agents to high-throughput conversational models.
-
35% faster responses: Vertex AI reduced Time to First Token (TTFT) latency by over 35% for Qwen3-Coder by using GKE Inference Gateway.
-
2x better tail latency: For bursty chat workloads, Vertex AI improved Time to First Token (TTFT) P95 latency by 2x (52%) for Deepseek V3.1 by using GKE Inference Gateway.
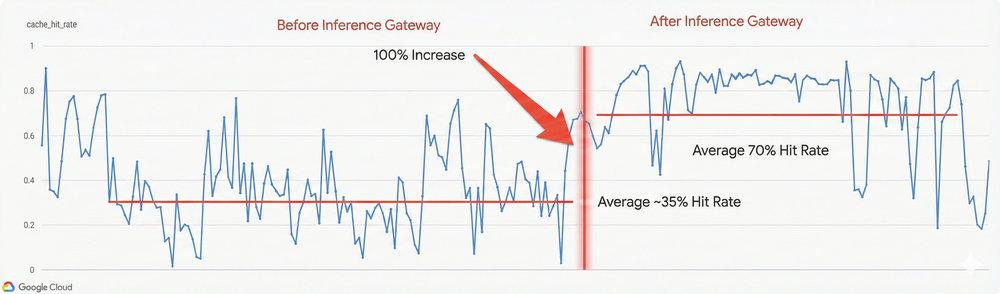
- Doubled efficiency: By leveraging the gateway’s prefix-caching awareness, Vertex AI doubled its prefix cache hit rate (from 35% to 70%) by adopting GKE Inference Gateway.
Deep dive: Two patterns for high-performance serving
Building a production-grade inference router is deceptively complex because AI traffic isn’t a single profile. At Vertex AI, we found that our workloads fell into two distinct traffic shapes, each requiring a different optimization strategy:
-
The context-heavy workload (e.g., coding agents): These requests involve massive context windows (like analyzing a whole codebase) that create sustained compute pressure. The bottleneck here is re-computation overhead.
-
The bursty workload (e.g., chat): These are unpredictable, stochastic spikes of short queries. The bottleneck here is queue congestion .
To handle both traffic profiles simultaneously, here are two specific engineering challenges Vertex AI solved using GKE Inference Gateway.
1. Tuning multi-objective load balancing
A standard round-robin load balancer doesn’t know which GPU holds the cached KV pairs for a specific prompt. This is particularly inefficient for ‘context-heavy’ workloads, where a cache miss means re-processing massive inputs from scratch. However, routing strictly for cache affinity can be dangerous; if everyone requests the same popular document, you create a node that gets overwhelmed while others sit idle.
The solution: Multi-objective tuning in GKE Inference Gateway uses a configurable scorer that balances conflicting signals. During the rollout of their new chat model, we here on the Vertex team tuned the weights for prefix:queue:kv-utilization.
By shifting the ratio from a default 3:3:2 to 3:5:2 (prioritizing queue depth slightly higher), we forced the scheduler to bypass “hot” nodes even if they had a cache hit. This configuration change immediately smoothed out traffic distribution while maintaining the high efficiency—doubling our prefix cache hit rate from 35% to 70%.
2. Managing queue depth for bursty traffic
Inference platforms often struggle with variable load, especially from sudden concurrent bursts. Without protection, these requests can saturate a model server, leading to resource contention that affects everyone in the queue.
The solution: Instead of letting these requests hit the model server directly, GKE Inference Gateway enforces admission control at the ingress layer. By managing the queue upstream, the system ensures that individual pods are never resource-starved.
The data proves the value: while median latency remained stable, the P95 latency improvement of 52% shows that the gateway successfully absorbed the variance that typically plagues AI applications during heavy load.
What this means for platform builders
Here’s our lesson: you don’t need to reinvent the scheduler.
Instead of maintaining custom infrastructure, you can use the GKE Inference Gateway. This gives you access to a scheduler proven by Google’s own internal workloads, ensuring you have robust protection against saturation without the maintenance overhead.
Ready to get started? Learn more about configuring GKE Inference Gateway for your workloads.

